
Expertise is what we want
Expertise is what we want

New study results: Novel AI architecture that overcomes key challenges in using AI for clinical workflows
At Color, we created a novel AI application architecture that is aimed at overcoming many of the main challenges that stand in the way of using GenAI in clinical decision-making. Some of these challenges include removing hallucinations, practically incorporating contextual logic that can be dependent on patient health insurance and site of care, and integrating with clinician workflows and judgement (i.e., how they think).
Across healthcare, but particularly in cancer, clinicians perform complex decision-making, which is often guided by standardized protocols established by various organizations and alliances. These guidelines—whether for workup assessments, screening protocols, or treatment pathways—are designed to ensure consistency and quality in patient care. These guidelines not only change frequently, but often vary based on context such as site of care, country, and a myriad of other variables.
Our most important realization is that at its heart, this is not purely a machine learning problem, but one that requires a declarative logic approach. To bridge this gap, we developed the Large Language Expert (LLE)—a novel hybrid architecture that combines the reasoning capabilities of an LLM with the rule-based precision of an Expert System (see our white paper). This approach is uniquely suited for domains where decisions must be both interpretable and rooted in established decision logic. To highlight the power of this architecture, we built an LLE-powered Cancer Copilot to assist with the workup of patients newly diagnosed with cancer. The system achieved a high degree of concordance with guidelines (> 95%) on a data set composed of anonymized real-world patients at UCSF Health.
The key insights driving the success of the LLE architecture are:
Alignment through declarative logic
Explicit extraction of decision factors to improve accuracy, inspectability, and feedback loops
Decomposition as a Chain-of-Thought (CoT) and multi-step reasoning mechanism enabling explainability & human intervention
Continuous improvement with foundation models
Alignment through declarative logic
Standardized guidelines exist to ensure consistency, reliability, and alignment with best practices in decision-making. By their very nature, they encode expert consensus. However, transforming these textual guidelines into structured, machine-interpretable logic is a crucial step in enabling AI-driven decision support.
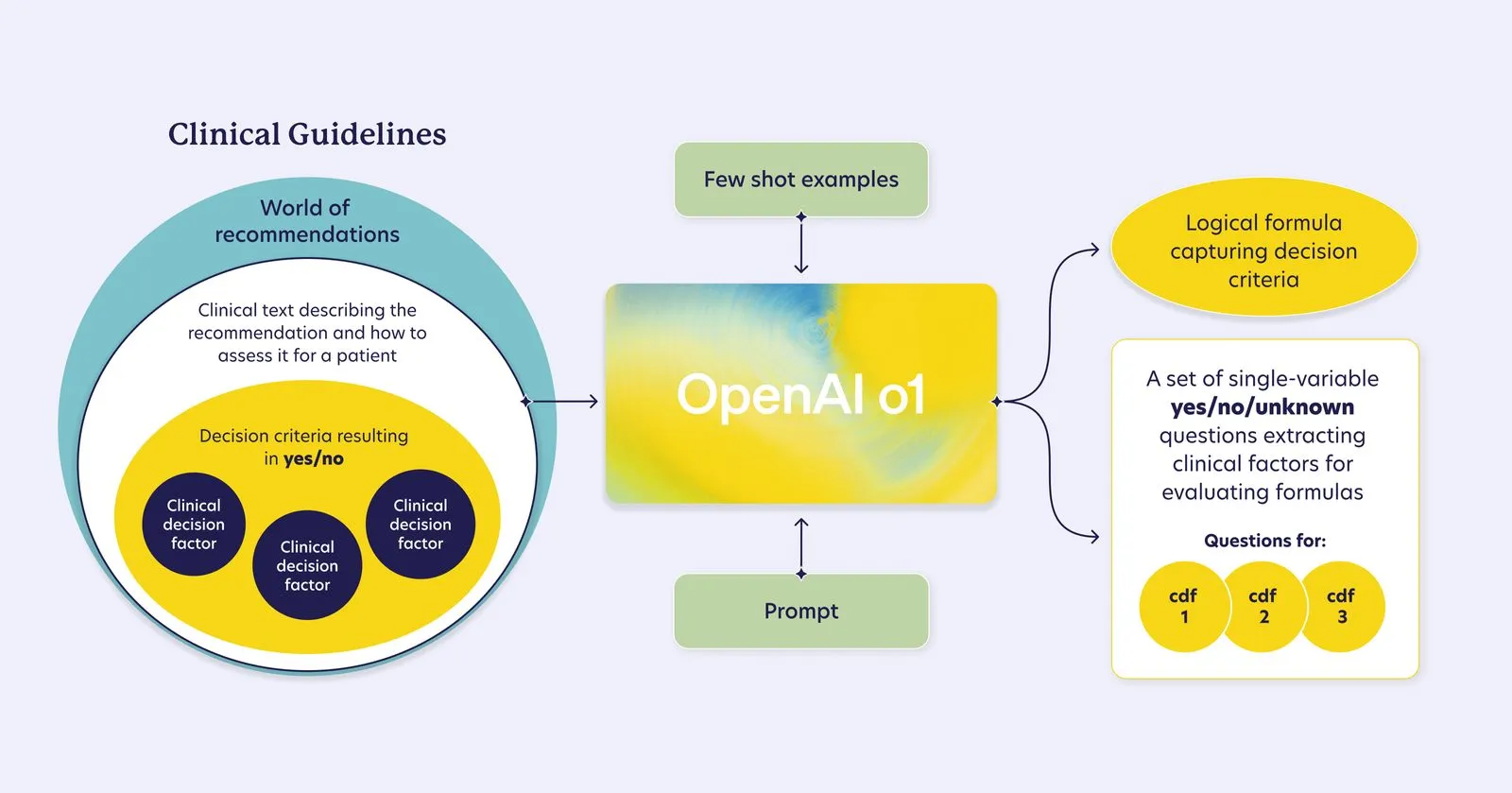
With the LLE, the first step is a pre-processing phase where we distill guidelines—originally described in natural language for clinicians—into two core components for every recommendation:
Clinical Decision Factors
We extract a set of uni-variate yes/no/unknown questions that capture the clinical criteria for evaluating a recommendation. For example, if “age > 70” is a relevant decision factor, we generate the question: “Is the patient’s age > 70?”Logical Decision Structure
We then construct a Boolean formula that defines how these decision factors combine to determine the validity of a recommendation. This ensures that every evaluation is interpretable, deterministic, and aligned with the original guideline intent.
By structuring guidelines in this way, the LLE preserves the alignment established through expert consensus in guideline development. This transformation requires a model that excels at understanding and formalizing natural language meaning into structured logic, a capability for which state of the art reasoning models (such as OpenAI’s o-series models) are particularly well-suited. Much like how these models are effective at generating code, they enable the LLE to translate clinical guidelines into a formal decision framework, ensuring precision and interpretability.
Explicit extraction of decision factors improves accuracy, inspectability, and feedback loops
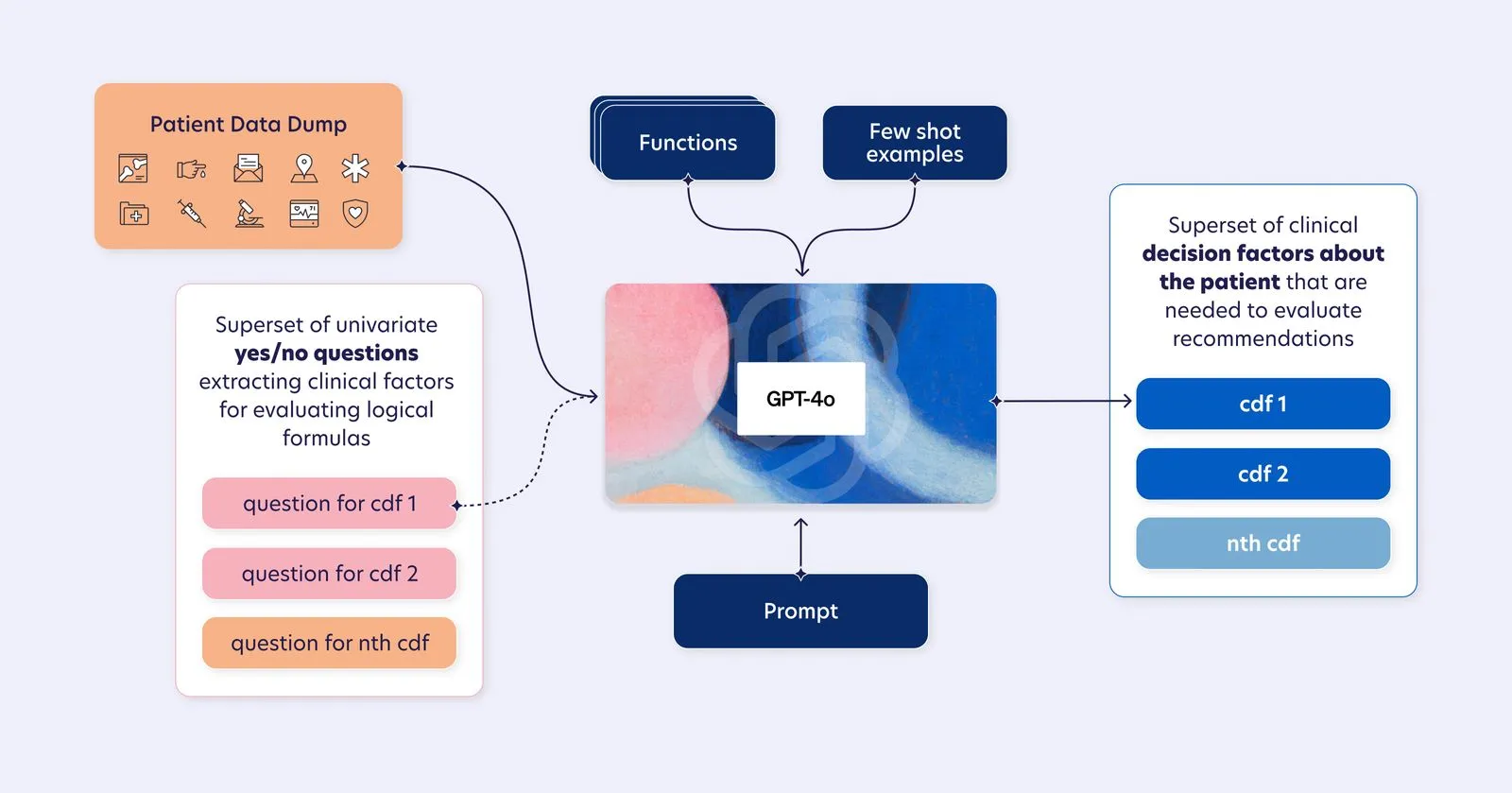
Once the guidelines have been pre-processed into structured decision criteria, the LLE enters the inference-time phase, where it evaluates a specific patient’s data to generate real-time, patient-specific recommendations.
In this phase, LLMs are leveraged in a targeted, well-defined capacity: answering the extracted clinical decision factor questions to determine the presence or absence of key clinical criteria for an individual patient. By limiting their role to this structured reasoning task, we ensure that LLMs operate within a controlled, inspectable scope, where their strengths in retrieval-based inference and pattern recognition can be fully utilized.
This focused application aligns with empirical evidence demonstrating that LLMs, particularly GPT-4o, excel at structured medical question-answering (Chen et al., 2024). By applying GPT-4o in this constrained manner, we leverage its generalization capabilities while maintaining tighter accuracy controls and slimmer error bounds. Rather than relying on broad, unconstrained inference, LLE harnesses LLMs specifically for structured reasoning tasks, ensuring that outputs are both interpretable and reliable.
Furthermore, this narrow scoping enables a more effective feedback loop. Because LLMs are confined to answering discrete, well-formed clinical decision factor questions, errors and inconsistencies become easier to pinpoint, analyze, and correct. When issues arise, in-context tuning and function calling allow for refining model behavior without modifying its underlying parameters. This makes the LLE not only more accurate upfront but also more adaptable over time, allowing for continuous system improvement through targeted interventions rather than broad, unpredictable model adjustments.
Decomposition as a CoT and multi-step reasoning mechanism enables explainability & human intervention
Once LLMs extract the clinical decision factors, the LLE enters the second runtime phase—logically evaluating candidate recommendations using the Boolean formulas distilled from clinical guidelines. This ensures that decision-making remains structured, rule-based, and aligned with expert consensus, reinforcing both accuracy and transparency.
However, ensuring interpretability and expert oversight requires more than just deterministic evaluation. To facilitate human intervention, LLE enhances each step with explanatory reasoning and evidence-backed outputs, integrating Chain-of-Thought (CoT) principles to provide contextual justifications at every stage.
Step 1: Extracting Clinical Decision Factors with Context and Supporting Evidence
In the first inference-time phase, the LLE does more than just answer clinical decision factor questions—it also explains why each answer is what it is. Instead of simply returning a ternary (yes/no/unknown), the model generates:
A reasoning trace describing why a particular factor applies to the patient.
Citations from the patient’s record supporting the decision.
This enriched output powers enhanced UX that is designed to facilitate expert oversight by surfacing both the decision and its justifications, ensuring that clinicians can intervene, validate, or correct based on the model’s reasoning.
Step 2: Logical Evaluation with Explainability-Driven Summaries
Once the clinical decision factors are extracted, the LLE architecture evaluates recommendations deterministically using the structured logic formulas derived in the guideline distillation step. However, instead of merely outputting a binary “recommended/not recommended” result, the LLE constructs an explanatory summary in a structured format designed to lend itself to expert review and intervention that includes:
A reasoning chain connecting the clinical decision factor responses to the final recommendation.
Guideline references explaining why this recommendation applies to the patient.
By integrating explanations directly into the recommendation output, the LLE ensures that every decision is accompanied by a clear, auditable reasoning process, making it easier for clinicians to validate and override recommendations when needed.
Continuous improvement alongside foundation models
The LLE architecture is designed to continuously improve as the foundation models it relies on—OpenAI’s o1 and GPT-4o—advance. Because foundation models are general-purpose reasoning engines, their improvements in capabilities like structured reasoning, code generation, and complex inference directly translate into better system performance for LLE-based applications.
Empirical research has shown that foundation model scaling leads to emergent improvements in complex reasoning tasks (Bommasani et al., 2021). The shift from GPT-3.5 to GPT-4 resulted in significant gains in medical reasoning, with GPT-4 achieving an 86.65% average score on the United States Medical Licensing Examination (USMLE), surpassing the passing threshold by over 20 points (Nori et al., 2023). These advances in clinical knowledge retrieval and structured medical reasoning directly benefit LLE’s ability to extract and apply clinical guidelines more effectively.
The impact is even clearer with o1, which plays a key role in LLE’s pre-processing phase, where it distills guidelines into formalized logic. OpenAI’s o1-preview model has demonstrated state-of-the-art performance in structured reasoning tasks such as code generation, achieving a 92.4% pass rate on the HumanEval benchmark (OpenAI). Additionally, o1-preview has set new benchmarks in mathematical reasoning, with a 0-shot CoT score of 94.8% on the MATH-500 dataset, highlighting its ability to translate complex natural language inputs into structured, formal representations (OpenAI). These exact capabilities are what enable LLE to efficiently distill clinical guidelines into structured, deterministic decision logic—and as the accuracy of o-series models continues to improve, so does this process.
The LLE system is designed to be model-agnostic, allowing it to seamlessly integrate advances in foundation models without requiring fundamental system changes. As these models continue to improve in reasoning depth, contextual awareness, and structured output generation, LLE’s accuracy, reliability, and adaptability improve in parallel.
By leveraging foundation models as a continuously advancing reasoning layer, LLE ensures that its ability to process, evaluate, and explain clinical guidelines remains state-of-the-art, making it more effective today—and even better tomorrow.
Conclusion
Viewed through this lens, the LLE architecture is more than a technical innovation—it represents a fundamental shift in how AI can support complex, guideline-driven decision-making. By merging the reasoning power of LLMs with the precision and structure of Expert Systems, LLE ensures that AI-driven recommendations remain accurate, interpretable, auditable, and aligned with expert consensus. This paradigm extends beyond oncology and clinical workflows to other high-stakes fields—such as regulatory compliance, financial risk assessment, and legal reasoning—where structured, evolving guidelines are essential for consistency and accountability. The same principles that drive LLE’s success in clinical decision-making can be applied across these domains, enabling AI to navigate complex rules while maintaining transparency and trust.
Additional Authors: Kiril Kafadarov, Amina Lazrak, Jayodita Sanghvi