News & Articles
Color Data: Expanding the capabilities of our open-access database
Mark Berger
Today, we are excited to announce a newly expanded Color Data, an open-access database with a cohort of 54,000 individuals and over 5.5 million variants.
Originally released over a year ago, Color Data is a publicly available database with genotypic and phenotypic information from individuals who have taken the Color test. A database largely built out of existing software and resources, it allows users to easily explore data by building custom queries with self-serve filters. Since its release in 2018, the site has been used as a data source for peer-reviewed publications and an educational reference for student-learning. All of the information in this database is from participants that generously consented to research, and we describe the measures we take to protect the privacy of these individuals (as well as database specifics) in our flagship publication.
Today’s new release expands data and features: In addition to an updated hereditary cancer dashboard, the database now includes a new dashboard for hereditary cardiovascular conditions. This dashboard contains genotypic information from 30 genes associated with hereditary cardiovascular conditions, along with self-reported phenotypic information (such as age, gender, and personal and family health history) from over 18,000 individuals.
By expanding the database to include hereditary cardiovascular conditions, researchers can now easily explore the interactions between genetic data and health history information for this disease area. For example, someone can filter by variant classification to identify the most common pathogenic variant in the dataset, which is a 25 base pair deletion in the MYBPC3 gene. MYBPC3 is an important gene for heart development and this 25 base pair mutation is associated with increased risk of cardiomyopathy. Upon further inspection, it turns out that 85% of individuals with this variant report being of Indian ethnicity:
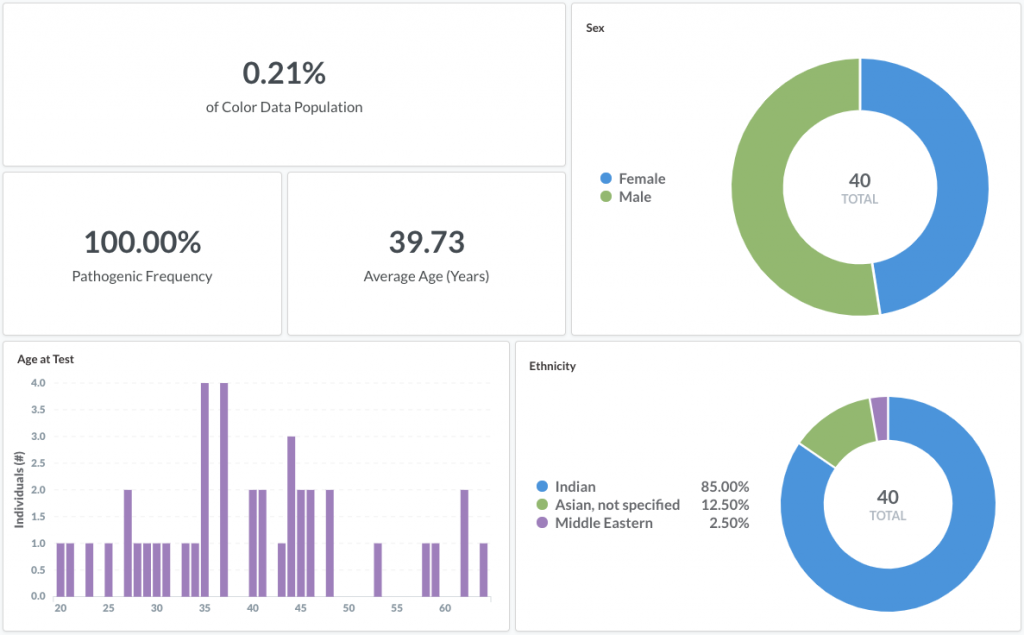
This deletion is a well-known pathogenic variant found at 2–8% frequency in Indian populations. Our hope is that this new dataset will allow researchers to reproduce other findings as well as discover novel interactions between genetic and health history information.
In addition to hereditary cardiovascular conditions, we have expanded Color Data to include clinical risk models and polygenic scores for cancer and heart conditions. Clinical risk models are commonly used by healthcare providers to estimate risk and guide patient care. These models use lifestyle information, such as cholesterol levels and BMI, to assess an individual’s risk of developing certain diseases. The clinical risk scores in this new release include breast cancer, atrial fibrillation, and coronary heart disease.
Polygenic scores are another type of risk model that use genetic information from many common variants across the genome to estimate disease risk. Research has demonstrated that polygenic scores can identify individuals at higher risk for certain conditions, sometimes with risks as high as people with a monogenic (single gene) pathogenic variant. At Color, we have pioneered a novel approach to calculate polygenic scores using low coverage whole genome sequencing in collaboration with Drs. Sekar Kathiresan and Amit V. Khera, and we are excited to include these scores in the database.
With Color Data, people can now easily explore how polygenic scores can be used to stratify risk in a population. For example, one can subset the Color Data hereditary cancer dashboard to females with a personal history of breast cancer:
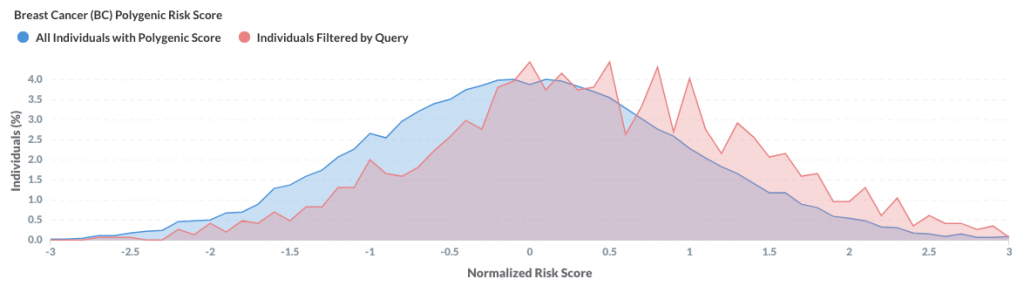
The graph shows polygenic scores for breast cancer risk are shifted to the right for females with a personal history of breast cancer compared to the entire population. This further demonstrates that the polygenic scores can be used to identify individuals with increased risk of developing breast cancer.
These two findings are just the beginning of what can be discovered with Color Data. We are excited for researchers to explore the new release, which is the product of collaboration between our research, engineering, design, and data science teams. For a detailed look at all of the new features and data in this release, read our pre-print publication.
We hope this new release will assist the scientific community in identifying genetic and non-genetic risk factors for disease. Exploring these relationships is a small step towards advancing human health and we are excited to see what everyone finds.
About Color
Color powers precision healthcare through cutting-edge technology. Color makes data-driven health programs such as clinical genetics accessible, convenient, and cost-effective for everyone. Color partners with leading health systems, premier employers, and national health initiatives around the world including the million-person All of Us Research Program by the National Institutes of Health. For more information about Color, visit www.color.com



